Internet Explorer redirect arbitrary file access vulnerability
Yorick Koster, June 2006
Abstract
A flaw has been discovered in the way Internet Explorer handles redirects. Using this flaw, it is possible to read the content of arbitrary web pages and/or arbitrary files. This issue can be triggered using a page that will redirect to itself the first time it is loaded. The second time this page is loaded, through the redirect, this page redirects to a different page. In this case, Internet Explorer will return the content of the new page as if it were the content of the page that performs the redirect. Using the XmlHttpRequest object, it is possible to read this content.
Tested versions
This issue has been tested using the following versions of Internet Explorer:
Internet Explorer 6.0 SP1 on Windows 2000 SP4 (updated May 2006)
Internet Explorer 6.0 SP2 on Windows XP SP2 (updated May 2006)
Internet Explorer 7.0 beta2 on Windows XP SP2 (updated May 2006)
All versions have been found to be affected by this issue. However, Internet Explorer 7 is only affected when this issue is exploited from the "Intranet" security zone.
Limitations
Some restrictions in Internet Explorer prevent an attacker from retrieving certain files. The most important restriction is caused by the security zones in Internet Explorer. A site running in a lower security zone (i.e. the Internet zone) is not allowed to read the content of a site running in a higher security zone (i.e. intranet zone). Also, the XmlHttpRequest does not properly process binary files. Consequently, when a binary file is loaded, it will be processed until the first NULL byte. The remainder of the file will be ignored.
Also, Internet Explorer 7.0 beta2 is affected by this issue, but currently the proof of concept only works from the intranet security zone. This is due to the fact that the 'new window' trick does not work in Internet Explorer 7. Furthermore, Internet Explorer 7 is not affected by AK20050801. Because of this, it is not possible to obtain local files using this issue.
Redirecting twice
A flaw has been discovered in the way Internet Explorer handles redirects. Using this flaw, an attacker can cause a different content to be loaded for the page that performed the redirect. This redirect has to occur in two steps. The first time a page is loaded, it should perform a redirect to itself. One way of achieving this is by returning the following HTML:
<html>
<script type="text/javascript" language="javascript">
location.reload(true);
</script>
</html>If the page reloads and this page redirects a second time, but to a different page, Internet Explorer will redirect to this other page. The content of this page is displayed by Internet Explorer. This redirect should be performed using the HTTP Location header. For example:
Location: http://www.microsoft.comWhen displaying the content of the redirect, Internet Explorer fails to update its address bar. At first, this appears to be a useless "address bar spoofing flaw", the same thing can be achieved using a frameset. Figure 1 shows this issue using a redirect to Google.
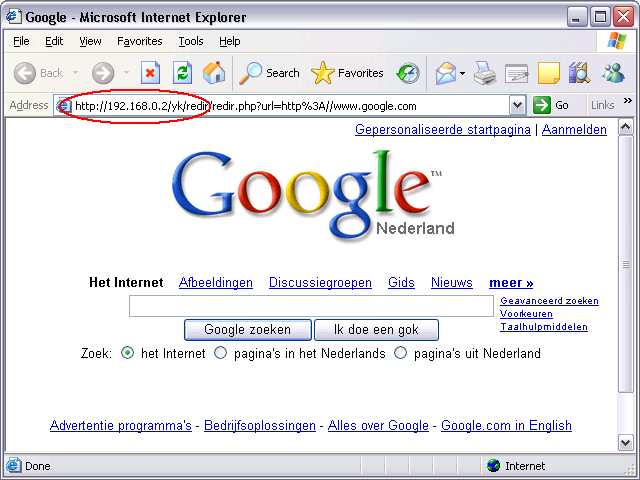
Figure 1: Redirecting to Google
Upon further investigation, it appears that it is actually possible for an attacker to read the content of the redirected page. This can be done using the XmlHttpRequest object. Under certain conditions, this object will follow redirects. Particularly, the XmlHttpRequest will do so if it is redirected to a page within the same domain as the page that executes the request. When it is redirected a second time as described above, the XmlHttpRequest object will also follow the redirect and return the content of that page. There are some limitations, for example the XmlHttpRequest object does not load the content if it is running in a higher security context (i.e. different security zone). See the limitations section for more information.
Internet zone vs. intranet zone
When loaded in the Internet zone, the XmlHttpRequest object behaves slightly different from when it is loaded in the intranet zone. If the attack, as described above, is performed from the Internet zone, the XmlHttpRequest object will trigger an access denied exception when it tries to the read the content of the redirected page. In order to avoid this exception, a new window has to be opened performing the redirect. After this window has loaded the target page, it is possible to use the XmlHttpRequest object to read the content of this page (by performing the redirect a second time). This time, no exception will be thrown.
Because of this, it is more difficult for an attacker to hide the attack. Also, the attack may be prevented by certain pop-up blocker applications.
Reading local files
Since Internet Explorer prevents sites running in a lower security zone to read files from pages running in a higher security zone, it is difficult to obtain files from the local machine zone. Normally, the attacker has to elevated security zones in order to do so. However, as described in AK20050801, it is possible to load local files in the intranet zone using a special file: URL. Because of this, sites running in the intranet security zone can obtain local files combining these two issues.
In order to read arbitrary local files one of the following conditions have to be met:
* The attack is performed from within the local network.
* A flaw in Internet Explorer allows an attacker to elevate a site running in the Internet zone to the intranet zone.
* The attacker is aware of a vulnerability in an intranet site, uses the target user as an intermediate to exploit this vulnerability, exploiting the redirect flaw.
Conclusion
Internet Explorer fails to correctly handle redirects, allowing an attacker to read arbitrary content from arbitrary websites (including intranet portals). Under certain conditions, it is even possible to obtain local files with the privileges of the target user.